Ejercicio Práctico - Estudio de Caso
Evaluación de Introducción a R y estadística
Introducción
Para concluir la sección de introducción, integremos todo lo aprendido para abordar un problema práctico. Usaremos el conjunto de datos oms del paquete datos que hemos utilizado en los módulos anteriores. Este dataset incluye información sobre la tuberculosis (TB), desglosada por año, país, edad, género y método de diagnóstico. Estos datos provienen del Informe de Tuberculosis de la Organización Mundial de la Salud 2014, que se puede encontrar en http://www.who.int/tb/country/data/download/en/.
Este dataset contiene mucha información epidemiológica, solo que tiene un detalle muy importante: los datos están muy sucios. Para limpiarlos y explorarlos, necesitamos aplicar todo lo que hemos aprendido en los módulos anteriores.
El objetivo es que puedas limpiar, explorar, visualizar y describir el dataset oms para obtener información relevante sobre la tuberculosis en el mundo. En la vida real, los datos que obtenemos rara vez están limpios y listos para ser analizados. Por lo tanto, es fundamental que sepas cómo limpiarlos y explorarlos para obtener información valiosa.
Preparación
Primero, vamos a cargar el dataset y a explorar su estructura. Desplazate con la barra de desplazamiento para ver todas las variables del dataset.
¿Qué problemas observas con este dataset? Observa que tiene: - Columnas redundantes. - Variables con nombres poco descriptivos. - Valores faltantes.
Si no sabemos qué significan las variables, es imposible analizar los datos. Sin embargo, recuerda que los datasets de R contienen información sobre las variables si llamamos al juego de datos con un argumento:
Solución
Recuerda los argumentos ?dataset y help(dataset).
Limpiar datos
A partir de la descripción del dataset que obtuviste en el ejercicio anterior, podemos ver distintos problemas. Vamos a limpiar los datos por partes antes de analizarlos
Existen 3 variables que se refieren a
país. vamos a quitar 2 de estas 3 variables. Idealmente, deberías quedarte con la variable que tiene el nombre del país ya en limpio.
- Después, tenemos una variable que indica año. Explora qué tipo de variable es y conviértela a una variable de tipo
factor(si es que aplica). Esto solo lo haremos para simplificar el análisis, pero recuerda que también podríamos analizarla como una variable numérica.
Solución
Recuerda la función mutate() y cómo usarla para cambiar el tipo de dato en este (link).
- Ahora, tenemos que solucionar el mayor problema de estos datos.
- Las
56columnas restantes son redundantes. Todas representan la cuenta de casos de TB, sin embargo, están desglosadas poredad,géneroymétodo de diagnóstico. - Podemos unir estas columnas en una sola variable que contenga la cuenta de casos de TB y así obtener un dataset con formato largo (una observación por fila).
- Si no recuerdas esto, puedes revisar la sección de Forma de Datos en este (link).
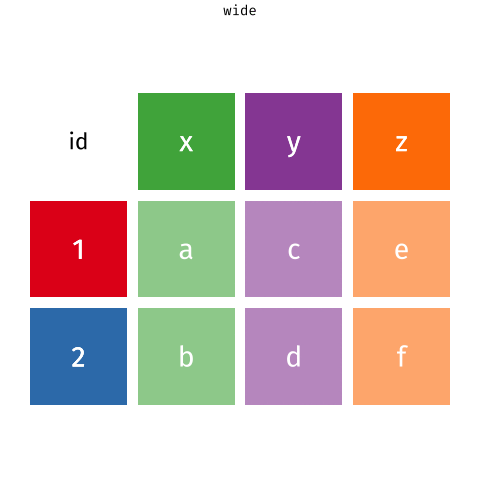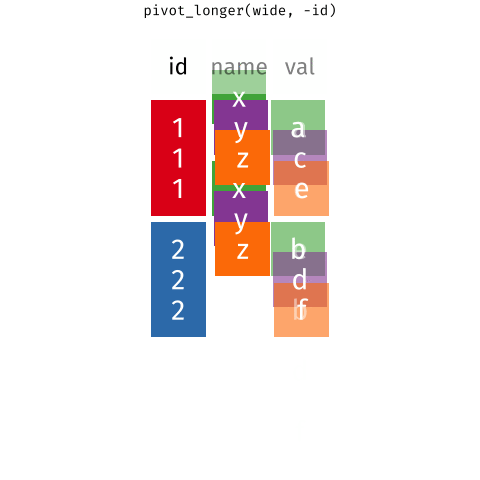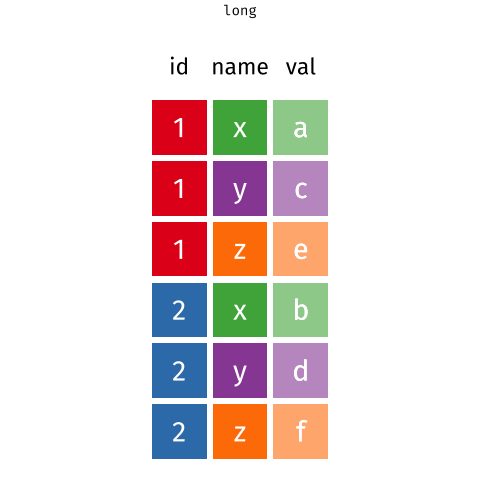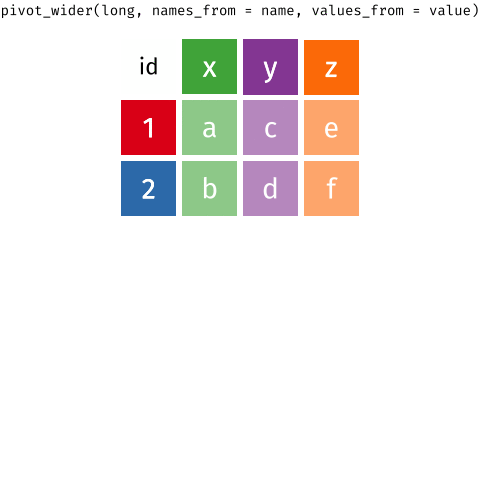

- Para juntar y agrupar en una sola variable, usaremos la función
pivot_longer()del paquetetidyr. - Aquí el reto es juntar las
56variables. La forma más fácil, pero menos práctica, sería específicar cada columna que queremos juntar. Sin embargo, podemos hacerlo de forma más eficiente. - Hay muchas formas para hacer esto. Mi recomndación es esta: observa que todas las columnas que queremos agrupar tienen un patrón común en su nombre. En la lección de manipulación de datos (link), revisa las funciones de ayuda de
dplyr. Analiza cuál de ellas te puede ayudar a resolver este problema: - Al correr el siguiente código, deberías tener un dataframe con 4 columnas:
pais,anio,claveycasosen un total de76046filas. - No te olvides cargar la librería necesaria para cargar la función
pivot_longer(). - Ojo: en este paso, también vamos a eliminar las filas con valores faltantes con el argumento
values_drop_na = TRUE.
Pista 1
Cuál de las siguientes funciones de ayuda te podría ayudar: starts_with(), ends_with(), contains(), matches(), num_range(), one_of(), everything().
- Ahora, pon atención en los nombres de la columna
clave. Estos nombres son poco descriptivos y no nos dicen mucho. Vamos a limpiarlos para que sean más descriptivos. - Si revisas la estructura de los datos, verás que los nombres de las columnas
clavesiguen ciertos patrones. - Cuando tienen las siguientes letras, significan lo siguiente:
recaidase refiere a casos reincidentesepse refiere a tuberculosis extra pulmonarfpnse refiere a casos de tuberculosis pulmonar que no se pueden detectar mediante examen de frotis pulmonar (frotis pulmonar negativo)fppse refiere a casos de tuberculosis pulmonar que se pueden detectar mediante examen de frotis pulmonar (frotis pulmonar positivo)- La letra que aparece después del último
_se refiere alsexode los pacientes. El conjunto de datos agrupa enhombres(h) ymujeres(m). - Los
númerosfinales se refieren al grupo deedadque se ha organizado ensietecategorías:- 014 = 0 – 14 años de edad
- 1524 = 15 – 24 años de edad
- 2534 = 25 – 34 años de edad
- 3544 = 35 – 44 años de edad
- 4554 = 45 – 54 años de edad
- 5564 = 55 – 64 años de edad
- 65 = 65 o más años de edad
- Idealmente, lo que queremos es que estos patrones se conviertan en variables separadas. Por ejemplo, si tenemos una columna
clavecon el nombrerecaida_ep_h_014, queremos que se convierta en 4 columnas:incidencia,ep,h,014. - Esto nos permitirá analizar los datos de forma más sencilla, por ejemplo, agrupando los casos por
sexoo poredad.
Verás que el problema anterior puede resolverse con solo dos funciones. - Para empezar, observa que los patrones que queremos extraer están separados por _; por ejemplo, recaida_ep_h_014, nuevos_ep_h1524, etc. - Por lo tanto, podemos usar una función que haga lo siguiente: tome cada dato de la columna clave y lo separe en distintas columnas cada vez que encuentre un _. - Antes de enseñarte a hacer esto, tenemos que resolver un problema antes te aplicar esta función. - Si observas la estructura de los datos, verás que hay casos en los que no se cumple el patrón que mencionamos. En específico, hay unos casos donde tenemos el patrón nuevosrecaida en lugar de nuevos_recaida. - Por lo tanto, tenemos que ver una forma de separar estos casos. - Para esto, hay un paquete del tidyverse que nos puede ayudar. Este paquete se llama stringr y tiene una función que nos permite hacer esto. - stringr es una referencia a los tipos de datos que se conocen como strings, que si recuerdas, son las cadenas de texto: “hola”, “mundo”, “recaida_ep_h_014”, etc.

- La función que nos va a ayudar a separar estos casos es
str_replace(). Esta función nos permite reemplazar un patrón en una cadena de texto por otro patrón. - Por lo tanto, para tener nombres consistentes, basta con reemplazar
nuevosrecaidapornuevos_recaida. - Esta función toma los siguientes argumentos:
str_replace(string, pattern, replacement).stringes la cadena de texto en la que queremos hacer el reemplazo.patternes el patrón que queremos reemplazar.replacementes el patrón por el que queremos reemplazar.
Respuesta
library(stringr) # Carga la librería necesaria
# Reemplaza los casos donde no se cumple el patrón
oms_5 <- oms_4 %>%
mutate(clave = str_replace(clave, "nuevosrecaida", "nuevos_recaida"))
head(oms_5) # Verificamos que se haya hecho correctamente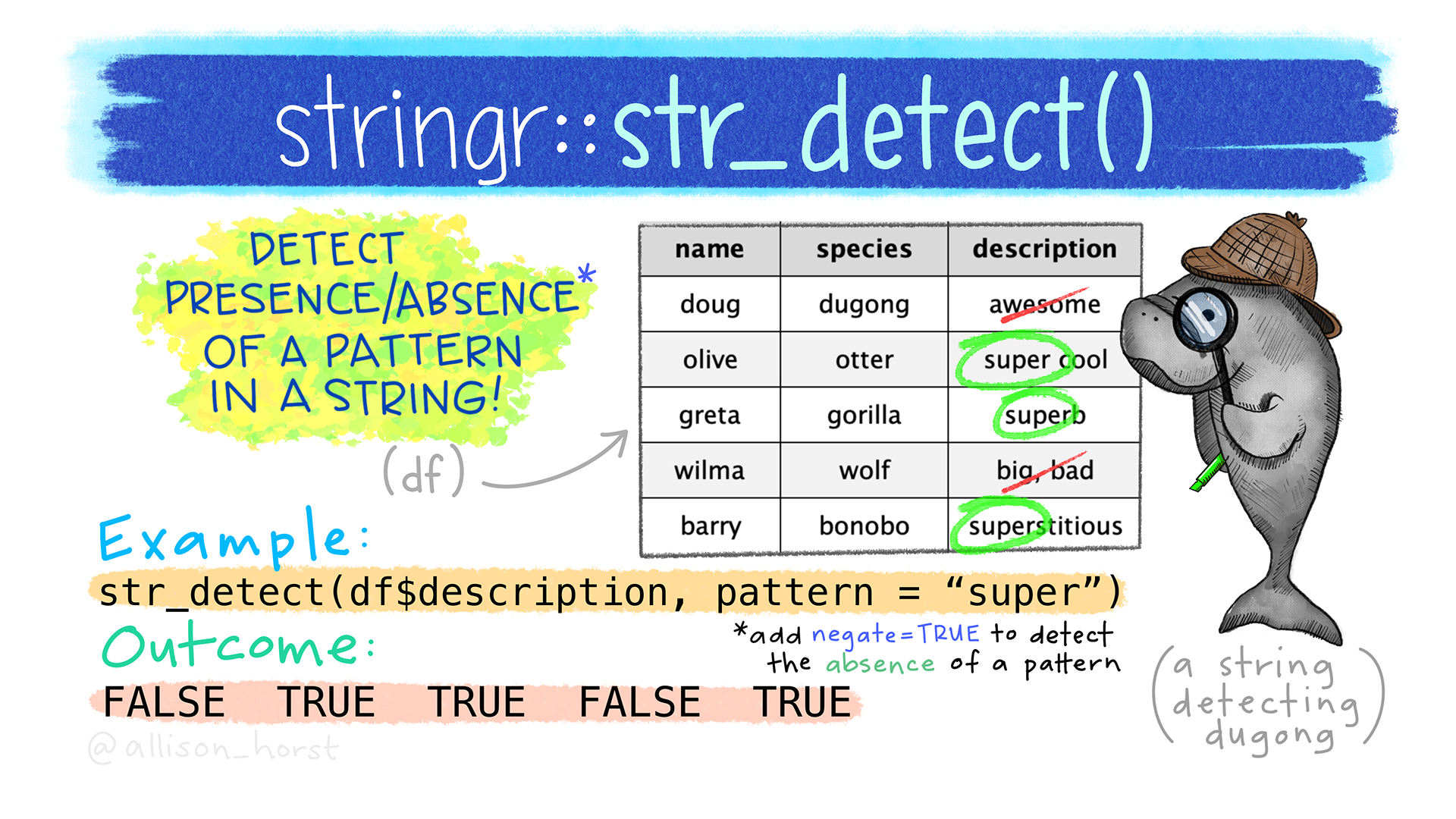
- Ahora, vamos a separar los patrones que mencionamos anteriormente.
- Para esto, usaremos la función
separate(). - Esta función es parte del paquete
tidyry nos permite separar una columna en varias columnas a partir de un patrón. - Tomará los siguientes argumentos:
separate(data, col, into, sep).dataes el dataframe que queremos modificar.coles la columna que queremos separar.intoes un vector con los nombres de las columnas en las que queremos separar la columna original.sepes el patrón que queremos usar para separar la columna original.
- Los nombres de las columnas que vamos a separar son:
nuevos,tipo,sexo_edad
Solución
# Separa los patrones de la columna clave
oms_6 <- oms_5 %>%
separate(clave, into = c("nuevos", "tipo", "sexo_edad"), sep = "_")
head(oms_6) # Verificamos que se haya hecho correctamente- A continuación podemos eliminar la columna nuevos, ya que es constante en este dataset.
Solución
Recuerda la función select().
- Para separar la columna
sexo_edaden dos columnas, usaremos la funciónseparate()de nuevo. - Observa los valores de esta columna; por ejemplo:
h014,m1524,m2534,h65etc. - ¿Qué patrón encuentras? ¿Cómo lo separarías en dos columnas?
- Una opción es usar
sep = x, dondexrepresenta un número. Este número indica la posición en la que queremos separar la cadena de texto. - Intenta el siguiente código para separar la columna
sexo_edaden dos columnas:sexoyedad.
Solución
separate(sexo_edad, c("sexo", "edad"), sep = 1)
Caso más complicado
- Imagina que la columna
sexo_edadtuviera un patrón más sucio, comoh24,027m,6h. - En estos casos, se usa lo que se conoce como
expresiones regulares. - Las expresiones regulares son patrones que se utilizan para encontrar secuencias de caracteres que conforma un patrón de búsqueda.
- Son extremadamente poderosas y útiles, pero también muy complicadas.
- Puedes leer más de ellas en el link de arriba. En este curso no las veremos, pero puedes conocerlas con este ejemplo.
- Si pasamos una expresión regular a
sep, podemos separar la cadena de texto en dos partes. Esta expresión regular es"(?<=\\d)(?=\\D)|(?<=\\D)(?=\\d)".\\dsignifica cualquier dígito.\\Dsignifica cualquier carácter que no sea un dígito.(?<=\\d)(?=\\D)significa que queremos separar la cadena de texto en dos partes: una que contenga letras y otra que contenga números.|significao.- Por lo tanto,
"(?<=\\d)(?=\\D)|(?<=\\D)(?=\\d)"significa que queremos separar la cadena de texto en dos partes: una que contenga letras y otra que contenga números.
- Por lo tanto, podrías usar
sep = "(?<=\\d)(?=\\D)|(?<=\\D)(?=\\d)"para separar la columnasexo_edaden dos columnas:sexoyedaden patrones más complicados y menos consistentes.
Todo en un solo paso…
- Cuando trabajas en datos, es normal que en un principio hagas las cosas paso a paso.
- Esto es bueno para entender cómo funcionan las funciones y cómo se aplican a los datos.
- Además, te permite verificar que cada paso se haya hecho correctamente.
- Sin embargo, una vez que entiendes cómo funcionan las funciones, puedes hacer todo en un solo paso.
- Esto es útil cuando tienes que hacer lo mismo con muchos datasets o cuando tienes que hacerlo de forma repetida.
- Encadena todos los pasos anteriores en una sola línea de código utilizando la pipa
%>%.
Si todo va bien hasta ahora, deberías de tener un dataset similar a este. En el siguiente ejercicio exploraremos estos datos limpios.