Resumen Funciones para Manejo de Datos
dplyr y tidyr
Introducción
Antes de continuar con el análisis estadístico de datos, es importante tener una comprensión sólida de cómo manipular y limpiar los datos. En R, las funciones de dplyr y tidyr son esenciales para este propósito. dplyr proporciona una gramática de manipulación de datos que facilita la selección, filtrado, ordenación, agrupación y resumen de datos. tidyr proporciona herramientas para cambiar la forma de los datos para que se ajusten a la estructura de datos “tidy” (ordenada). En este resumen, revisaremos las funciones más comunes de dplyr y tidyr para manipular y limpiar datos en R.
dplyr

Para este resumen, utilizaremos el conjunto de datos iris, que contiene medidas de flores. Este conjunto de datos viene incorporado en R y se puede cargar con el comando data("iris"). Los datos provienen de un estudio sobre la variabilidad de las flores de iris (Ronald Fisher, 1936) y contienen cuatro medidas (longitud y ancho del sépalo y pétalo) de tres especies de iris (setosa, versicolor y virginica).
Primero, cargaremos la librería dplyr y el conjunto de datos iris.
Sintáxis básica en dplyr
El primer argumento siempre es un dataframe. Sin embargo, si utiliza el operador%>% (pipe), se puede omitir el primer argumento ya que se detecta automáticamente. Ejemplo:
Inspeccionar Datos
glimpse()
- La función
glimpse()dedplyrproporciona una descripción concisa de un conjunto de datos. - Muestra el tipo de datos de cada columna y las primeras observaciones.
Tip
Si estás en RStudio, puedes ver los datos en un formato de hoja de cálculo (tipo Excel) con View(iris).
View(iris)arrange()
- La función
arrange()dedplyrordena las filas de un data frame por los valores de una columna. - Por ejemplo, para ordenar las filas de
irispor la columnaSepal.Lengthde menor a mayor, se puede usararrange(iris, Sepal.Length).
Limpiar Datos
janitor::clean_names()
- La función
clean_names()dejanitorlimpia los nombres de las columnas de un data frame. - Esto es muy útil cuando tienes nombres de columnas con espacios, mayúsculas, caracteres especiales (‘ñ’), etc. Esto puede causar errores en R, por lo que es recomendable limpiar los nombres de las columnas.
- Esta función convierte los nombres de las columnas a minúsculas, elimina espacios y caracteres especiales, y reemplaza los espacios con guiones bajos.
rename()
- La función
rename()dedplyrcambia el nombre de las columnas de un data frame. - Por ejemplo, para cambiar el nombre de la columna
Speciesaespecie, se puede usarrename(iris, especie = Species).
Filtrar Datos
seleccionar columnas
- La función
select()dedplyrselecciona columnas de un data frame.

- Por ejemplo, para seleccionar las columnas
Sepal.Width,Petal.LengthySpeciesdeiris, se puede usarselect(iris, Sepal.Width, Petal.Length, Species).
- Para quitar una columna, se puede usar el signo
-antes del nombre de la columna. Por ejemplo, para quitar la columnaSpeciesdeiris, se puede usarselect(iris, -Species).
Funciones de ayuda
starts_with(): selecciona columnas cuyos nombres comienzan con una cadena de caracteres.
ends_with(): selecciona columnas cuyos nombres terminan con una cadena de caracteres.
Otras funciones similares:
select(iris, contains(".")): Selecciona columnas cuyos nombres contienen una cadena de caracteres.select(iris, everything()): Selecciona todas las columnas.select(iris, num_range("x", 1:5)): Selecciona columna con nombres x1, x2, x3, x4, x5.select(iris, one_of(c("Species", "Genus"))): Selecciona columnas cuyos nombres están en un grupo de nombres.
seleccionar filas u observaciones
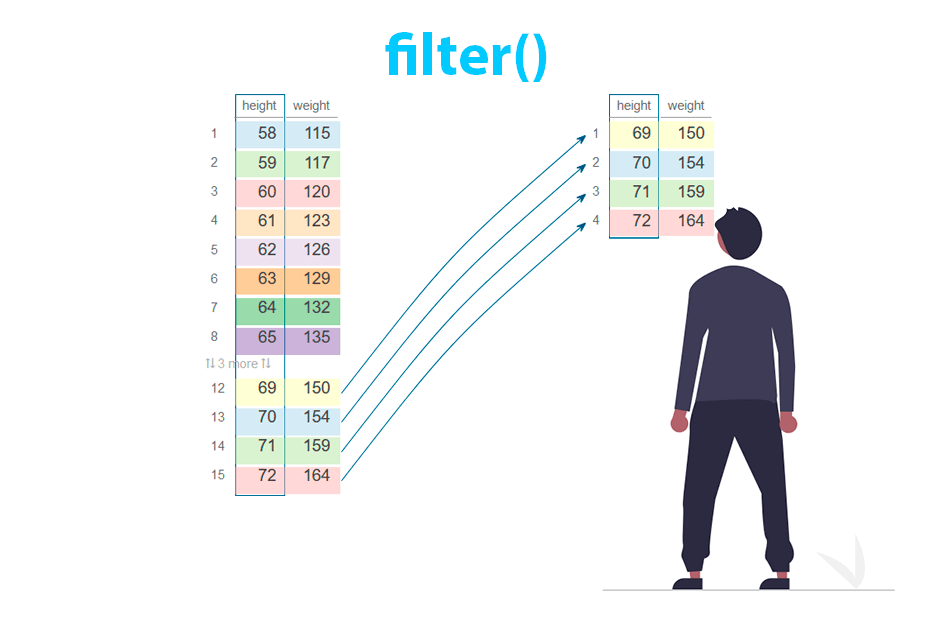
- La función
filter()dedplyrfiltra filas de un data frame que cumplen ciertos criterios. - Por ejemplo, para filtrar las filas de
irisdondeSepal.Lengthes mayor que 7, se puede usarfilter(iris, Sepal.Length > 7).
Recuerda los Operadores lógicos que podemos usar en R:
==: igual a
!=: no igual a
>: mayor que,<: menor que,>=: mayor o igual que,<=: menor o igual que
%in%: pertenece a un conjunto
&: y lógico,|: o lógico- En nuestro ejemplo, ninguna fila cumple con la condición de Sepal.Length > 7 y Species == “setosa”.
is.na(): es NA- En nuestro ejemplo, no hay filas donde Sepal.Length es NA.
Otras funciones útiles para filtrar datos:
distinct(): Remueve filas duplicadas.- en nuestro ejemplo, no hay filas duplicadas en
iris.
sample_frac(): Selecciona una fracción de filas al azar.- Observa como cada vez que ejecutas el código, obtienes un subconjunto diferente de filas.
sample_n(): Selecciona n filas al azar.
top_n(): Selecciona y ordena las n entradas más altas (por grupo si los datos están agrupados).
Resumiendo Datos
- La función
summarise()dedplyrresume datos a una sola fila de valores. - Por ejemplo, para calcular el promedio de
Sepal.Lengtheniris, se puede usarsummarise(iris, avg = mean(Sepal.Length)).
- Podemos resumir varias columnas con varias funciones estadísticas a la vez:
count(): Cuenta el número de valores únicos para cada variable.
n(): Número de observaciones en un grupo.
n_distinct(): Número de valores distintos en un vector.
pull(): Extrae una columna como un vector.
Agrupando Datos
group_by(): Agrupa datos en filas por los valores en una o más columnas.
Crear Nuevas Variables
mutate(): Calcula y añade una o más columnas nuevas.
case_when(): Reemplaza valores basados en condiciones.- En el siguiente ejemplo, reemplazamos los valores de
Speciespor el nombre científico completo. - Piensalo como un
if-elseen R. Es decir, siSpecieses “setosa”, reemplazarlo con “Iris setosa”, si es “versicolor”, reemplazarlo con “Iris versicolor”, y si es “virginica”, reemplazarlo con “Iris virginica”.
Cambiar tipo de datos
- Podemos usar
mutate()para cambiar el tipo de datos de una columna: as.factor(): Convierte una columna a un factor.as.character(): Convierte una columna a un carácter.as.numeric(): Convierte una columna a un número.as.integer(): Convierte una columna a un entero.- En el siguiente ejemplo, vamos a convertir la columna
Sepal.Lengtha un factor (esto no tiene sentido real, solo es para ilustrar).
tidyr

Cambiar la Forma de los Datos
- La forma de los datos es fundamental para el análisis de datos. Los datos “ordenados” o “tidy” tienen una observación por fila y una variable por columna, como en la siguiente figura:

- Sin embargo, los datos reales a menudo no están en esta forma ordenada.
tidyrproporciona herramientas para cambiar la forma de los datos para que se ajusten a la estructura de datos “tidy”. - Ve el siguiente ejemplo, donde los datos están en una forma “ancha” y se convierten en una forma “larga” o “tidy” con
pivot_longer(). - Ancho (wide) se refiere a tener muchas columnas para una misma variable, mientras que en el formato largo (long) se tiene una columna para cada variable.
- ve la siguiente imagen, donde se muestra la diferencia entre los formatos ancho y largo. En la forma ancha (derecha), la variable de año está en dos columnas: 1999 y 2000. En la forma larga (izquierda), la variable de año está en una sola columna llamada “año” y los valores correspondientes están en una columna llamada “valor”.

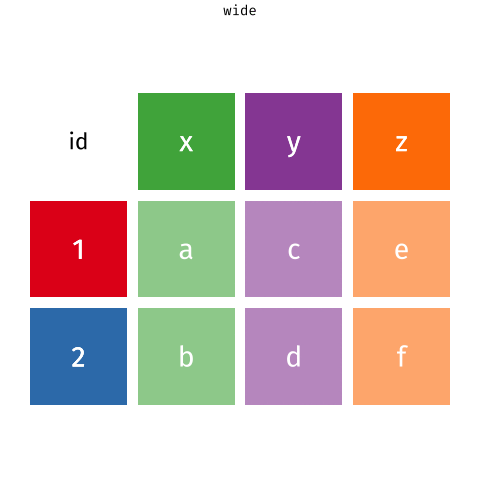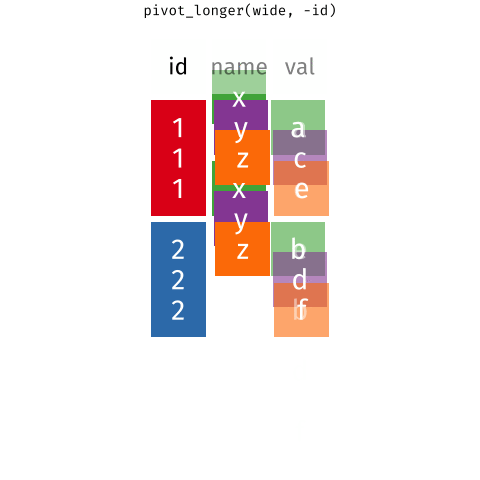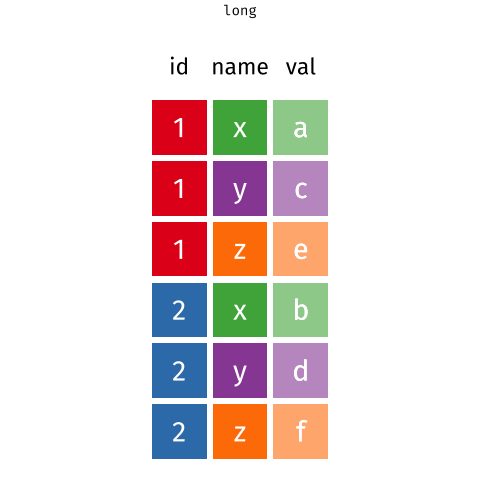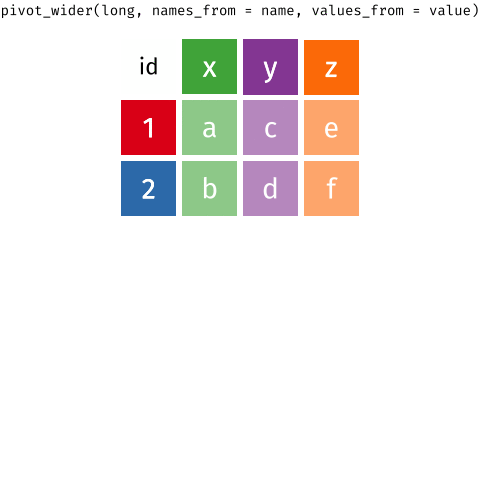
- lo que queremos hacer es convertir los datos de la forma ancha a la forma larga. Para hacer esto, usamos la función
pivot_longer()detidyr. Su funcionamiento se ejemplifica en la siguiente imagen:
- Para usar
pivot_longer(), se especifican las columnas que se quieren convertir en filas y en qué columnas se quieren mantener. Por ejemplo, para convertir las columnas1999y2000en filas y mantener la columnapais, se puede usarpivot_longer(datos, cols = c(1999, 2000), names_to = "año", values_to = "valor"). - En este ejemplo,
colsespecifica las columnas que se convertirán en filas,names_toespecifica el nombre de la columna que contendrá los nombres de las columnas convertidas en filas, yvalues_toespecifica el nombre de la columna que contendrá los valores correspondientes.
- ahora convertimos los datos de la forma ancha a la forma larga con
pivot_longer().
pivot_wider(): Convierte los datos de la forma larga a la forma ancha.pivot_wider()es el opuesto depivot_longer(). Convierte los datos de la forma larga a la forma ancha. Por ejemplo, para convertir los datos de la forma larga a la forma ancha, se puede usarpivot_wider(datos, names_from = año, values_from = valor). Este formato es útil para algunos casos que se verán más adelante.- En este ejemplo,
names_fromespecifica la columna que contiene los nombres de las nuevas columnas, yvalues_fromespecifica la columna que contiene los valores correspondientes. - Ve el siguiente ejemplo, donde los datos están en una forma “larga” y se convierten en una forma “ancha” con
pivot_wider().
- ahora convertimos los datos de la forma larga a la forma ancha con
pivot_wider().